Anti-patterns:
In software engineering, an anti-pattern (or antipattern) is a design pattern that appears obvious but is ineffective or far from optimal in practice.1 Or as I like to think of it, the type of code that makes you want to rip your eyes out, like in that movie Event Horizon...
Identity Theft
Here's a pattern that I had witnessed several times in a particular codebase, which I believe suffers from some design flaws:
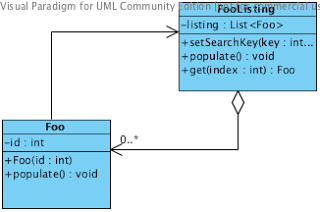
FooListing is a class that retrieves and maintains a list of Foo objects
Description
FooListingis a repository-type object that holds a list of Foo objects, which it populates
from the database using its populate() function. The Foo object also has a populate()
method, but this method instantiates a FooListing, and uses the FooListing populate function
with its key - so now the FooListingcontains the desired Fooobject. Our original Foo
object now contains a reference to the Fooobject that it wants to be - so it does what
anyone would do, steals its identity and hides the body.
Foo.populate() looks something like this:
public void populate() {
FooListing listing = new FooListing()
// Set up FooListing
FooListing.setSearchKey(id);
if (listing.size > 0) {
Foo foo = listing.get(0);
this.setBar(foo.getBar);
// continue to copy over properties
// ...
} else {
LOG.warn("Foo not found for key: " + id);
}
}Why this is bad
Firstly, apart from the questional morality, it
is duplicated code. FooListing already has the capability to create and
populate a Foo object from the database. Two locations for this code means
twice the maintenance if something changes, more possibility
of bugs, etc.
Foo and FooListing have become tightly coupled and
dependant on each other under this design - there is a cyclic dependancy which
is a code smell, and may cause headaches when writing unit tests.
There is also a waste of resoures creating the uneccesary FooListingand Foo
objects inside of Foo.populate(), at least some of that could be avoided by
client code accessing instances of Foo via FooListing.populate.
It also doesn't make sense that a data access object like Fooshould be concerned
with information about how it is created. Fooshould act more like a bean,
or an immutable class.
Another dangerous aspect of this design is the
implication that client code accessing Foo cannot be certain that Foo has
been instantiated correctly. If the client code has a faulty key for Foo
that does not exist in the database, when it creates new Foo(key) there is
no way to know that Foo.populate() has failed to find the correct value, and
instead they are left with a faulty Foo instance which was not what they
requested.
Solution
The best solution for this isolated pattern is to
completely remove (or deprecate) the Foo.populate() method, and replace
calls to it with FooListing instances.
If FooListing fails to find a
matching Foo, the client code should realise this when FooListing returns
them a null object. The client code can handle and recover from this case in
context.
Implementing a getFirstResult() function in FooListing could
be beneficial if there are many cases where the code with otherwise be calling
get(0).
We could also simplify the calling code so that retrieving a
result is a one-line operation - i.e. get() calls populate() if the list
has not already been populated.
public final class FooListing {
private List<Foo$gt; _listing;
private int _id;
public FooListing {
}
public FooListing(int id) {
_searchId = id;
}
public void populate() {
_listing = new ArrayList<foo>();
// Query the database and add to _listing
}
public Foo get(int index) {
if (_listing == null) {
populate();
}
if (_listing.isEmpty() || index >= _listing.size()) {
return null;
} else {
return _listing.get(index);
}
}
public Foo getFirstResult() {
return this.get(0);
}
public List<foo> getList() {
return _listing;
}
public void setSearchId(int id) {
_id = id;
}
}And the client code would only need to call:
Foo foo = new FooListing(id).getFirstResult();